Guide
Basics
Introduction
A probabilistic program is Julia code wrapped in a @model macro. It can use arbitrary Julia code, but to ensure correctness of inference it should not have external effects or modify global state. Stack-allocated variables are safe, but mutable heap-allocated objects may lead to subtle bugs when using task copying. By default Libtask deepcopies Array and Dict objects when copying task to avoid bugs with data stored in mutable structure in Turing models.
To specify distributions of random variables, Turing programs should use the ~ notation:
x ~ distr where x is a symbol and distr is a distribution. If x is undefined in the model function, inside the probabilistic program, this puts a random variable named x, distributed according to distr, in the current scope. distr can be a value of any type that implements rand(distr), which samples a value from the distribution distr. If x is defined, this is used for conditioning in a style similar to Anglican (another PPL). In this case, x is an observed value, assumed to have been drawn from the distribution distr. The likelihood is computed using logpdf(distr,y). The observe statements should be arranged so that every possible run traverses all of them in exactly the same order. This is equivalent to demanding that they are not placed inside stochastic control flow.
Available inference methods include Importance Sampling (IS), Sequential Monte Carlo (SMC), Particle Gibbs (PG), Hamiltonian Monte Carlo (HMC), Hamiltonian Monte Carlo with Dual Averaging (HMCDA) and The No-U-Turn Sampler (NUTS).
Simple Gaussian Demo
Below is a simple Gaussian demo illustrate the basic usage of Turing.jl.
# Import packages.
using Turing
using StatsPlots
# Define a simple Normal model with unknown mean and variance.
@model function gdemo(x, y)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
x ~ Normal(m, sqrt(s²))
return y ~ Normal(m, sqrt(s²))
end
gdemo (generic function with 2 methods)
Note: As a sanity check, the prior expectation of s² is mean(InverseGamma(2, 3)) = 3/(2 - 1) = 3 and the prior expectation of m is 0. This can be easily checked using Prior:
p1 = sample(gdemo(missing, missing), Prior(), 100000)
Chains MCMC chain (100000×5×1 Array{Float64, 3}):
Iterations = 1:1:100000
Number of chains = 1
Samples per chain = 100000
Wall duration = 1.82 seconds
Compute duration = 1.82 seconds
parameters = s², m, x, y
internals = lp
Summary Statistics
parameters mean std mcse ess_bulk ess_tail
rha ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Flo
at6 ⋯
s² 3.0015 6.8154 0.0215 98326.8468 99009.0896 1.
000 ⋯
m 0.0028 1.7294 0.0055 99587.6486 97264.8932 1.
000 ⋯
x 0.0073 2.4605 0.0078 100639.0941 98876.4601 1.
000 ⋯
y 0.0020 2.4426 0.0077 99820.3511 99635.6484 1.
000 ⋯
2 columns om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s² 0.5332 1.1119 1.7859 3.1279 12.3881
m -3.3937 -0.9117 -0.0021 0.9110 3.4128
x -4.7947 -1.2641 0.0067 1.2778 4.7928
y -4.8021 -1.2902 0.0075 1.2891 4.8201
We can perform inference by using the sample function, the first argument of which is our probabilistic program and the second of which is a sampler. More information on each sampler is located in the API.
# Run sampler, collect results.
c1 = sample(gdemo(1.5, 2), SMC(), 1000)
c2 = sample(gdemo(1.5, 2), PG(10), 1000)
c3 = sample(gdemo(1.5, 2), HMC(0.1, 5), 1000)
c4 = sample(gdemo(1.5, 2), Gibbs(PG(10, :m), HMC(0.1, 5, :s²)), 1000)
c5 = sample(gdemo(1.5, 2), HMCDA(0.15, 0.65), 1000)
c6 = sample(gdemo(1.5, 2), NUTS(0.65), 1000)
Chains MCMC chain (1000×14×1 Array{Float64, 3}):
Iterations = 501:1:1500
Number of chains = 1
Samples per chain = 1000
Wall duration = 1.59 seconds
Compute duration = 1.59 seconds
parameters = s², m
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, max_hamiltonian_energy_error,
tree_depth, numerical_error, step_size, nom_step_size
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
s² 1.9780 1.4619 0.0704 480.7501 548.1521 0.9999
⋯
m 1.1699 0.8446 0.0409 466.5292 298.0476 1.0004
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s² 0.5398 1.0422 1.5820 2.3635 6.4282
m -0.4188 0.6261 1.1312 1.6526 3.0863
The MCMCChains module (which is re-exported by Turing) provides plotting tools for the Chain objects returned by a sample function. See the MCMCChains repository for more information on the suite of tools available for diagnosing MCMC chains.
# Summarise results
describe(c3)
# Plot results
plot(c3)
savefig("gdemo-plot.png")
The arguments for each sampler are:
- SMC: number of particles.
- PG: number of particles, number of iterations.
- HMC: leapfrog step size, leapfrog step numbers.
- Gibbs: component sampler 1, component sampler 2, ...
- HMCDA: total leapfrog length, target accept ratio.
- NUTS: number of adaptation steps (optional), target accept ratio.
For detailed information on the samplers, please review Turing.jl's API documentation.
Modelling Syntax Explained
Using this syntax, a probabilistic model is defined in Turing. The model function generated by Turing can then be used to condition the model onto data. Subsequently, the sample function can be used to generate samples from the posterior distribution.
In the following example, the defined model is conditioned to the data (arg1 = 1, arg2 = 2) by passing (1, 2) to the model function.
@model function model_name(arg_1, arg_2)
return ...
end
The conditioned model can then be passed onto the sample function to run posterior inference.
model_func = model_name(1, 2)
chn = sample(model_func, HMC(..)) # Perform inference by sampling using HMC.
The returned chain contains samples of the variables in the model.
var_1 = mean(chn[:var_1]) # Taking the mean of a variable named var_1.
The key (:var_1) can be a Symbol or a String. For example, to fetch x[1], one can use chn[Symbol("x[1]")] or chn["x[1]"].
If you want to retrieve all parameters associated with a specific symbol, you can use group. As an example, if you have the
parameters "x[1]", "x[2]", and "x[3]", calling group(chn, :x) or group(chn, "x") will return a new chain with only "x[1]", "x[2]", and "x[3]".
Turing does not have a declarative form. More generally, the order in which you place the lines of a @model macro matters. For example, the following example works:
# Define a simple Normal model with unknown mean and variance.
@model function model_function(y)
s ~ Poisson(1)
y ~ Normal(s, 1)
return y
end
sample(model_function(10), SMC(), 100)
Chains MCMC chain (100×3×1 Array{Float64, 3}):
Log evidence = -23.513623996503505
Iterations = 1:1:100
Number of chains = 1
Samples per chain = 100
Wall duration = 1.67 seconds
Compute duration = 1.67 seconds
parameters = s
internals = lp, weight
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
s 3.9900 0.1000 0.0100 100.0801 NaN 1.0000
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s 4.0000 4.0000 4.0000 4.0000 4.0000
But if we switch the s ~ Poisson(1) and y ~ Normal(s, 1) lines, the model will no longer sample correctly:
# Define a simple Normal model with unknown mean and variance.
@model function model_function(y)
y ~ Normal(s, 1)
s ~ Poisson(1)
return y
end
sample(model_function(10), SMC(), 100)
Sampling Multiple Chains
Turing supports distributed and threaded parallel sampling. To do so, call sample(model, sampler, parallel_type, n, n_chains), where parallel_type can be either MCMCThreads() or MCMCDistributed() for thread and parallel sampling, respectively.
Having multiple chains in the same object is valuable for evaluating convergence. Some diagnostic functions like gelmandiag require multiple chains.
If you do not want parallelism or are on an older version Julia, you can sample multiple chains with the mapreduce function:
# Replace num_chains below with however many chains you wish to sample.
chains = mapreduce(c -> sample(model_fun, sampler, 1000), chainscat, 1:num_chains)
The chains variable now contains a Chains object which can be indexed by chain. To pull out the first chain from the chains object, use chains[:,:,1]. The method is the same if you use either of the below parallel sampling methods.
Multithreaded sampling
If you wish to perform multithreaded sampling and are running Julia 1.3 or greater, you can call sample with the following signature:
using Turing
@model function gdemo(x)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in eachindex(x)
x[i] ~ Normal(m, sqrt(s²))
end
end
model = gdemo([1.5, 2.0])
# Sample four chains using multiple threads, each with 1000 samples.
sample(model, NUTS(), MCMCThreads(), 1000, 4)
Be aware that Turing cannot add threads for you -- you must have started your Julia instance with multiple threads to experience any kind of parallelism. See the Julia documentation for details on how to achieve this.
Distributed sampling
To perform distributed sampling (using multiple processes), you must first import Distributed.
Process parallel sampling can be done like so:
# Load Distributed to add processes and the @everywhere macro.
using Distributed
# Load Turing.
using Turing
# Add four processes to use for sampling.
addprocs(4; exeflags="--project=$(Base.active_project())")
# Initialize everything on all the processes.
# Note: Make sure to do this after you've already loaded Turing,
# so each process does not have to precompile.
# Parallel sampling may fail silently if you do not do this.
@everywhere using Turing
# Define a model on all processes.
@everywhere @model function gdemo(x)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in eachindex(x)
x[i] ~ Normal(m, sqrt(s²))
end
end
# Declare the model instance everywhere.
@everywhere model = gdemo([1.5, 2.0])
# Sample four chains using multiple processes, each with 1000 samples.
sample(model, NUTS(), MCMCDistributed(), 1000, 4)
Sampling from an Unconditional Distribution (The Prior)
Turing allows you to sample from a declared model's prior. If you wish to draw a chain from the prior to inspect your prior distributions, you can simply run
chain = sample(model, Prior(), n_samples)
You can also run your model (as if it were a function) from the prior distribution, by calling the model without specifying inputs or a sampler. In the below example, we specify a gdemo model which returns two variables, x and y. The model includes x and y as arguments, but calling the function without passing in x or y means that Turing's compiler will assume they are missing values to draw from the relevant distribution. The return statement is necessary to retrieve the sampled x and y values.
Assign the function with missing inputs to a variable, and Turing will produce a sample from the prior distribution.
@model function gdemo(x, y)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
x ~ Normal(m, sqrt(s²))
y ~ Normal(m, sqrt(s²))
return x, y
end
gdemo (generic function with 2 methods)
Assign the function with missing inputs to a variable, and Turing will produce a sample from the prior distribution.
# Samples from p(x,y)
g_prior_sample = gdemo(missing, missing)
g_prior_sample()
(0.9993424270217681, 3.906774556760344)
Sampling from a Conditional Distribution (The Posterior)
Treating observations as random variables
Inputs to the model that have a value missing are treated as parameters, aka random variables, to be estimated/sampled. This can be useful if you want to simulate draws for that parameter, or if you are sampling from a conditional distribution. Turing supports the following syntax:
@model function gdemo(x, ::Type{T}=Float64) where {T}
if x === missing
# Initialize `x` if missing
x = Vector{T}(undef, 2)
end
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in eachindex(x)
x[i] ~ Normal(m, sqrt(s²))
end
end
# Construct a model with x = missing
model = gdemo(missing)
c = sample(model, HMC(0.01, 5), 500)
Chains MCMC chain (500×14×1 Array{Float64, 3}):
Iterations = 1:1:500
Number of chains = 1
Samples per chain = 500
Wall duration = 1.49 seconds
Compute duration = 1.49 seconds
parameters = s², m, x[1], x[2]
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, numerical_error, step_size, no
m_step_size
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
s² 4.6103 2.7851 1.8029 3.2957 28.2197 1.2385
⋯
m -0.0947 0.3807 0.3220 1.4933 21.5892 1.9081
⋯
x[1] -1.4767 0.3998 0.1605 6.1629 10.8662 1.1108
⋯
x[2] 5.1851 0.2488 0.1647 2.3892 26.0620 1.3382
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s² 1.5111 2.1967 3.4091 6.8342 10.3627
m -0.6753 -0.3806 -0.1698 0.2395 0.6017
x[1] -2.2428 -1.7482 -1.4889 -1.2253 -0.5607
x[2] 4.7541 4.9848 5.2171 5.3458 5.7054
Note the need to initialize x when missing since we are iterating over its elements later in the model. The generated values for x can be extracted from the Chains object using c[:x].
Turing also supports mixed missing and non-missing values in x, where the missing ones will be treated as random variables to be sampled while the others get treated as observations. For example:
@model function gdemo(x)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in eachindex(x)
x[i] ~ Normal(m, sqrt(s²))
end
end
# x[1] is a parameter, but x[2] is an observation
model = gdemo([missing, 2.4])
c = sample(model, HMC(0.01, 5), 500)
Chains MCMC chain (500×13×1 Array{Float64, 3}):
Iterations = 1:1:500
Number of chains = 1
Samples per chain = 500
Wall duration = 1.46 seconds
Compute duration = 1.46 seconds
parameters = s², m, x[1]
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, numerical_error, step_size, no
m_step_size
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
s² 0.9241 0.1734 0.1087 2.6552 12.1962 1.3058
⋯
m 0.7694 0.2983 0.2444 1.4688 20.4061 1.9265
⋯
x[1] 0.6833 0.2334 0.0815 8.7687 22.2620 1.0238
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s² 0.5668 0.8166 0.9312 1.0484 1.2321
m 0.1234 0.5821 0.8232 0.9649 1.3028
x[1] 0.2335 0.5110 0.7217 0.8490 1.1198
Default Values
Arguments to Turing models can have default values much like how default values work in normal Julia functions. For instance, the following will assign missing to x and treat it as a random variable. If the default value is not missing, x will be assigned that value and will be treated as an observation instead.
using Turing
@model function generative(x=missing, ::Type{T}=Float64) where {T<:Real}
if x === missing
# Initialize x when missing
x = Vector{T}(undef, 10)
end
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in 1:length(x)
x[i] ~ Normal(m, sqrt(s²))
end
return s², m
end
m = generative()
chain = sample(m, HMC(0.01, 5), 1000)
Chains MCMC chain (1000×22×1 Array{Float64, 3}):
Iterations = 1:1:1000
Number of chains = 1
Samples per chain = 1000
Wall duration = 2.91 seconds
Compute duration = 2.91 seconds
parameters = s², m, x[1], x[2], x[3], x[4], x[5], x[6], x[7], x[8],
x[9], x[10]
internals = lp, n_steps, is_accept, acceptance_rate, log_density, h
amiltonian_energy, hamiltonian_energy_error, numerical_error, step_size, no
m_step_size
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
s² 0.6992 0.2206 0.0725 8.4106 17.7949 1.1427
⋯
m -0.2297 0.2386 0.0725 13.5465 13.2908 1.0425
⋯
x[1] 0.0148 0.3010 0.0941 10.7942 18.1768 1.1316
⋯
x[2] 0.8719 0.5344 0.2870 3.5589 12.2675 1.3721
⋯
x[3] -0.6714 0.4263 0.2623 2.7271 38.3192 1.9730
⋯
x[4] -0.7221 0.4383 0.1664 7.6176 12.9420 1.1834
⋯
x[5] -0.5877 0.4355 0.1514 8.4450 20.2703 1.0461
⋯
x[6] -0.0462 0.3478 0.1090 10.7685 12.3098 1.0360
⋯
x[7] 0.0064 0.2918 0.1247 6.2445 57.4716 1.1968
⋯
x[8] -0.6242 0.2577 0.0732 13.9780 42.5638 1.0237
⋯
x[9] -0.5508 0.2086 0.0867 5.7638 22.0132 1.2790
⋯
x[10] -0.0714 0.5175 0.1991 7.5553 45.2729 1.0267
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
s² 0.3799 0.5399 0.6691 0.7979 1.2548
m -0.6232 -0.3908 -0.2498 -0.1008 0.3383
x[1] -0.6052 -0.1988 0.0406 0.2199 0.5383
x[2] -0.2074 0.5399 0.9341 1.2198 2.0008
x[3] -1.4906 -0.8895 -0.6749 -0.3534 0.0607
x[4] -1.5220 -0.9823 -0.7480 -0.4731 0.2303
x[5] -1.4090 -0.8988 -0.5678 -0.2970 0.3784
x[6] -0.6376 -0.3024 -0.0875 0.1772 0.7246
x[7] -0.4530 -0.2319 -0.0297 0.2165 0.5826
x[8] -1.0858 -0.7961 -0.6686 -0.4499 -0.0641
x[9] -0.9762 -0.6912 -0.5520 -0.4090 -0.1514
x[10] -0.9004 -0.5048 -0.0564 0.3862 0.8204
Access Values inside Chain
You can access the values inside a chain several ways:
- Turn them into a
DataFrameobject - Use their raw
AxisArrayform - Create a three-dimensional
Arrayobject
For example, let c be a Chain:
DataFrame(c)convertscto aDataFrame,c.valueretrieves the values insidecas anAxisArray, andc.value.dataretrieves the values insidecas a 3DArray.
Variable Types and Type Parameters
The element type of a vector (or matrix) of random variables should match the eltype of the its prior distribution, <: Integer for discrete distributions and <: AbstractFloat for continuous distributions. Moreover, if the continuous random variable is to be sampled using a Hamiltonian sampler, the vector's element type needs to either be:
Realto enable auto-differentiation through the model which uses special number types that are sub-types ofReal, or- Some type parameter
Tdefined in the model header using the type parameter syntax, e.g.function gdemo(x, ::Type{T} = Float64) where {T}. Similarly, when using a particle sampler, the Julia variable used should either be: - An
Array, or - An instance of some type parameter
Tdefined in the model header using the type parameter syntax, e.g.function gdemo(x, ::Type{T} = Vector{Float64}) where {T}.
Querying Probabilities from Model or Chain
Consider first the following simplified gdemo model:
@model function gdemo0(x)
s ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s))
return x ~ Normal(m, sqrt(s))
end
# Instantiate three models, with different value of x
model1 = gdemo0(1)
model4 = gdemo0(4)
model10 = gdemo0(10)
DynamicPPL.Model{typeof(Main.var"##WeaveSandBox#501".gdemo0), (:x,), (), ()
, Tuple{Int64}, Tuple{}, DynamicPPL.DefaultContext}(Main.var"##WeaveSandBox
#501".gdemo0, (x = 10,), NamedTuple(), DynamicPPL.DefaultContext())
Now, query the instantiated models: compute the likelihood of x = 1.0 given the values of s = 1.0 and m = 1.0 for the parameters:
prob"x = 1.0 | model = model1, s = 1.0, m = 1.0"
0.39894228040143265
prob"x = 1.0 | model = model4, s = 1.0, m = 1.0"
0.39894228040143265
prob"x = 1.0 | model = model10, s = 1.0, m = 1.0"
0.39894228040143265
Notice that even if we use three models, instantiated with three different values of x, we should obtain the same likelihood. We can easily verify that value in this case:
pdf(Normal(1.0, 1.0), 1.0)
0.3989422804014327
Let us now consider the following gdemo model:
@model function gdemo(x, y)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
x ~ Normal(m, sqrt(s²))
return y ~ Normal(m, sqrt(s²))
end
# Instantiate the model.
model = gdemo(2.0, 4.0)
DynamicPPL.Model{typeof(Main.var"##WeaveSandBox#501".gdemo), (:x, :y), (),
(), Tuple{Float64, Float64}, Tuple{}, DynamicPPL.DefaultContext}(Main.var"#
#WeaveSandBox#501".gdemo, (x = 2.0, y = 4.0), NamedTuple(), DynamicPPL.Defa
ultContext())
The following are examples of valid queries of the Turing model or chain:
-
prob"x = 1.0, y = 1.0 | model = model, s = 1.0, m = 1.0"calculates the likelihood ofx = 1andy = 1givens = 1andm = 1. -
prob"s² = 1.0, m = 1.0 | model = model, x = nothing, y = nothing"calculates the joint probability ofs = 1andm = 1ignoringxandy.xandyare ignored so they can be optionally dropped from the RHS of|, but it is recommended to define them. -
prob"s² = 1.0, m = 1.0, x = 1.0 | model = model, y = nothing"calculates the joint probability ofs = 1,m = 1andx = 1ignoringy. -
prob"s² = 1.0, m = 1.0, x = 1.0, y = 1.0 | model = model"calculates the joint probability of all the variables. -
After the MCMC sampling, given a
chain,prob"x = 1.0, y = 1.0 | chain = chain, model = model"calculates the element-wise likelihood ofx = 1.0andy = 1.0for each sample inchain. -
If
save_state=truewas used during sampling (i.e.,sample(model, sampler, N; save_state=true)), you can simply doprob"x = 1.0, y = 1.0 | chain = chain".
In all the above cases, logprob can be used instead of prob to calculate the log probabilities instead.
Maximum likelihood and maximum a posterior estimates
Turing provides support for two mode estimation techniques, maximum likelihood estimation (MLE) and maximum a posterior (MAP) estimation. Optimization is performed by the Optim.jl package. Mode estimation is currently a optional tool, and will not be available to you unless you have manually installed Optim and loaded the package with a using statement. To install Optim, run import Pkg; Pkg.add("Optim").
Mode estimation only works when all model parameters are continuous -- discrete parameters cannot be estimated with MLE/MAP as of yet.
To understand how mode estimation works, let us first load Turing and Optim to enable mode estimation, and then declare a model:
# Note that loading Optim explicitly is required for mode estimation to function,
# as Turing does not load the opimization suite unless Optim is loaded as well.
using Turing
using Optim
@model function gdemo(x)
s² ~ InverseGamma(2, 3)
m ~ Normal(0, sqrt(s²))
for i in eachindex(x)
x[i] ~ Normal(m, sqrt(s²))
end
end
gdemo (generic function with 6 methods)
Once the model is defined, we can construct a model instance as we normally would:
# Create some data to pass to the model.
data = [1.5, 2.0]
# Instantiate the gdemo model with our data.
model = gdemo(data)
DynamicPPL.Model{typeof(Main.var"##WeaveSandBox#501".gdemo), (:x,), (), (),
Tuple{Vector{Float64}}, Tuple{}, DynamicPPL.DefaultContext}(Main.var"##Wea
veSandBox#501".gdemo, (x = [1.5, 2.0],), NamedTuple(), DynamicPPL.DefaultCo
ntext())
Mode estimation is typically quick and easy at this point. Turing extends the function Optim.optimize and accepts the structs MLE() or MAP(), which inform Turing whether to provide an MLE or MAP estimate, respectively. By default, the LBFGS optimizer is used, though this can be changed. Basic usage is:
# Generate a MLE estimate.
mle_estimate = optimize(model, MLE())
# Generate a MAP estimate.
map_estimate = optimize(model, MAP())
ModeResult with maximized lp of -4.62
[0.9074074072600302, 1.1666666671196524]
If you wish to change to a different optimizer, such as NelderMead, simply place your optimizer in the third argument slot:
# Use NelderMead
mle_estimate = optimize(model, MLE(), NelderMead())
# Use SimulatedAnnealing
mle_estimate = optimize(model, MLE(), SimulatedAnnealing())
# Use ParticleSwarm
mle_estimate = optimize(model, MLE(), ParticleSwarm())
# Use Newton
mle_estimate = optimize(model, MLE(), Newton())
# Use AcceleratedGradientDescent
mle_estimate = optimize(model, MLE(), AcceleratedGradientDescent())
Some methods may have trouble calculating the mode because not enough iterations were allowed, or the target function moved upwards between function calls. Turing will warn you if Optim fails to converge by running Optim.converge. A typical solution to this might be to add more iterations, or allow the optimizer to increase between function iterations:
# Increase the iterations and allow function eval to increase between calls.
mle_estimate = optimize(
model, MLE(), Newton(), Optim.Options(; iterations=10_000, allow_f_increases=true)
)
More options for Optim are available here.
Analyzing your mode estimate
Turing extends several methods from StatsBase that can be used to analyze your mode estimation results. Methods implemented include vcov, informationmatrix, coeftable, params, and coef, among others.
For example, let's examine our ML estimate from above using coeftable:
# Import StatsBase to use it's statistical methods.
using StatsBase
# Print out the coefficient table.
coeftable(mle_estimate)
─────────────────────────────
estimate stderror tstat
─────────────────────────────
s 0.0625 0.0625 1.0
m 1.75 0.176777 9.8995
─────────────────────────────
Standard errors are calculated from the Fisher information matrix (inverse Hessian of the log likelihood or log joint). t-statistics will be familiar to frequentist statisticians. Warning -- standard errors calculated in this way may not always be appropriate for MAP estimates, so please be cautious in interpreting them.
Sampling with the MAP/MLE as initial states
You can begin sampling your chain from an MLE/MAP estimate by extracting the vector of parameter values and providing it to the sample function with the keyword init_params. For example, here is how to sample from the full posterior using the MAP estimate as the starting point:
# Generate an MAP estimate.
map_estimate = optimize(model, MAP())
# Sample with the MAP estimate as the starting point.
chain = sample(model, NUTS(), 1_000; init_params=map_estimate.values.array)
Beyond the Basics
Compositional Sampling Using Gibbs
Turing.jl provides a Gibbs interface to combine different samplers. For example, one can combine an HMC sampler with a PG sampler to run inference for different parameters in a single model as below.
@model function simple_choice(xs)
p ~ Beta(2, 2)
z ~ Bernoulli(p)
for i in 1:length(xs)
if z == 1
xs[i] ~ Normal(0, 1)
else
xs[i] ~ Normal(2, 1)
end
end
end
simple_choice_f = simple_choice([1.5, 2.0, 0.3])
chn = sample(simple_choice_f, Gibbs(HMC(0.2, 3, :p), PG(20, :z)), 1000)
Chains MCMC chain (1000×3×1 Array{Float64, 3}):
Iterations = 1:1:1000
Number of chains = 1
Samples per chain = 1000
Wall duration = 14.09 seconds
Compute duration = 14.09 seconds
parameters = p, z
internals = lp
Summary Statistics
parameters mean std mcse ess_bulk ess_tail rhat
e ⋯
Symbol Float64 Float64 Float64 Float64 Float64 Float64
⋯
p 0.4537 0.2054 0.0203 102.7765 159.4336 1.0073
⋯
z 0.1680 0.3741 0.0177 445.2764 NaN 0.9993
⋯
1 column om
itted
Quantiles
parameters 2.5% 25.0% 50.0% 75.0% 97.5%
Symbol Float64 Float64 Float64 Float64 Float64
p 0.0878 0.2944 0.4395 0.6004 0.8662
z 0.0000 0.0000 0.0000 0.0000 1.0000
The Gibbs sampler can be used to specify unique automatic differentiation backends for different variable spaces. Please see the Automatic Differentiation article for more.
For more details of compositional sampling in Turing.jl, please check the corresponding paper.
Working with filldist and arraydist
Turing provides filldist(dist::Distribution, n::Int) and arraydist(dists::AbstractVector{<:Distribution}) as a simplified interface to construct product distributions, e.g., to model a set of variables that share the same structure but vary by group.
Constructing product distributions with filldist
The function filldist provides a general interface to construct product distributions over distributions of the same type and parameterisation.
Note that, in contrast to the product distribution interface provided by Distributions.jl (Product), filldist supports product distributions over univariate or multivariate distributions.
Example usage:
@model function demo(x, g)
k = length(unique(g))
a ~ filldist(Exponential(), k) # = Product(fill(Exponential(), k))
mu = a[g]
return x .~ Normal.(mu)
end
demo (generic function with 2 methods)
Constructing product distributions with arraydist
The function arraydist provides a general interface to construct product distributions over distributions of varying type and parameterisation.
Note that in contrast to the product distribution interface provided by Distributions.jl (Product), arraydist supports product distributions over univariate or multivariate distributions.
Example usage:
@model function demo(x, g)
k = length(unique(g))
a ~ arraydist([Exponential(i) for i in 1:k])
mu = a[g]
return x .~ Normal.(mu)
end
demo (generic function with 2 methods)
Working with MCMCChains.jl
Turing.jl wraps its samples using MCMCChains.Chain so that all the functions working for MCMCChains.Chain can be re-used in Turing.jl. Two typical functions are MCMCChains.describe and MCMCChains.plot, which can be used as follows for an obtained chain chn. For more information on MCMCChains, please see the GitHub repository.
describe(chn) # Lists statistics of the samples.
plot(chn) # Plots statistics of the samples.
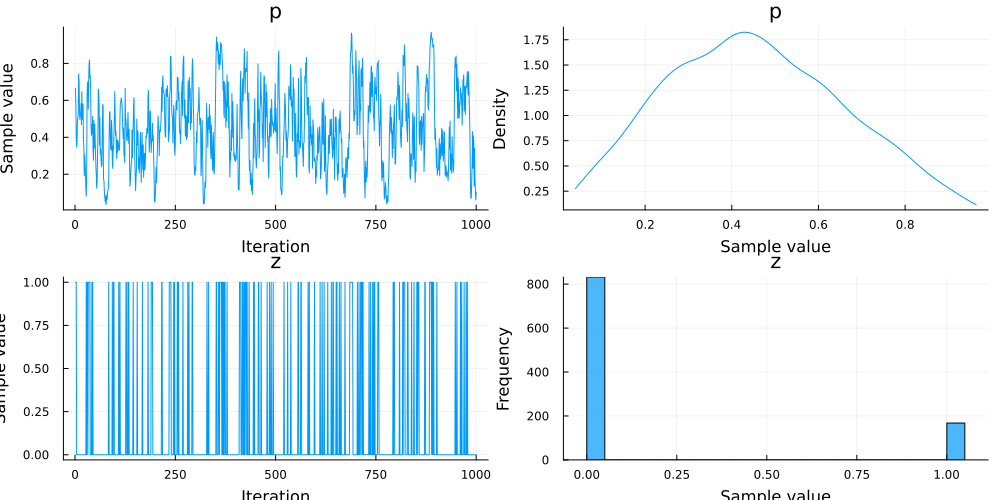
There are numerous functions in addition to describe and plot in the MCMCChains package, such as those used in convergence diagnostics. For more information on the package, please see the GitHub repository.
Changing Default Settings
Some of Turing.jl's default settings can be changed for better usage.
AD Chunk Size
ForwardDiff (Turing's default AD backend) uses forward-mode chunk-wise AD. The chunk size can be set manually by setchunksize(new_chunk_size).
AD Backend
Turing supports four packages of automatic differentiation (AD) in the back end during sampling. The default AD backend is ForwardDiff for forward-mode AD. Three reverse-mode AD backends are also supported, namely Tracker, Zygote and ReverseDiff. Zygote and ReverseDiff are supported optionally if explicitly loaded by the user with using Zygote or using ReverseDiff next to using Turing.
For more information on Turing's automatic differentiation backend, please see the Automatic Differentiation article.
Progress Logging
Turing.jl uses ProgressLogging.jl to log the progress of sampling. Progress
logging is enabled as default but might slow down inference. It can be turned on
or off by setting the keyword argument progress of sample to true or false, respectively. Moreover, you can enable or disable progress logging globally by calling setprogress!(true) or setprogress!(false), respectively.
Turing uses heuristics to select an appropriate visualization backend. If you use Juno, the progress is displayed with a progress bar in the Atom window. For Jupyter notebooks the default backend is ConsoleProgressMonitor.jl. In all other cases, progress logs are displayed with TerminalLoggers.jl. Alternatively, if you provide a custom visualization backend, Turing uses it instead of the default backend.